
 By
Doug 'The Data Guy' Needham
By
Doug 'The Data Guy' Needham
.jpg?width=1600&height=1000&name=wallpaperflare.com_wallpaper%20(1).jpg)
The toolset around implementing a Data Vault continues to grow. Once a decision has been made to implement Data Vault, there are still further choices to be made to make the Data Vault implementation successful. Using the DataOps.live Data Platform can make these choices simpler to implement. Our Data Platform can abstract the various tools such that the only thing needed in our platform is configuration information showing the tools what to do. The Automation of Snowflake is built into our platform. Running a pipeline will produce the proper environment around the Data Vault that it needs.
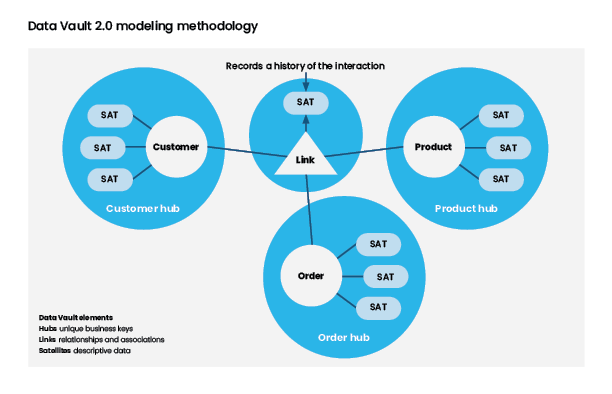
More can be said about Data Vault than can be covered adequately in a simple blog post. The essence of Data Vault modeling and implementation is that tables are created using three main structures:
- HUB
- LINK
- SATELITE
One of the most important topics when designing a Data Vault structure is the business key. A business or natural key is the key that the business uses to identify their records in the source systems. I think of things like account number or customer ID number, chances are these keys are not primary keys on the tables, yet they are the keys I use as a customer when interacting with a business.
A hub is a set of unique business keys. This table pattern can be loaded from multiple systems that share business keys across various systems. In the diagram above these are the white circles with the labels.
A link is the relationship between business keys. These relationships could be transactions, hierarchies, ownership, and other types of relationships. A link can be a relationship between two or more hubs. In the diagram above the link is the triangle in the middle.
A Satellite is a time-dimensional table housing detailed information about the hubs or links business keys. In the diagram above these are the ellipses connected to either the hubs or links.
As I said at the beginning of this article, more can be said about Data Vault than what I intend to cover here, so I would suggest reaching out to the inventor of Data Vault, Dan Linstedt if you want to learn more. He will point you in the right direction.
Our founders did a video describing the relationship between Data Vault and Dataops.live some time ago. The essence of the video has not changed even though our software has matured with new capabilities.
The DataOps.live data platform can augment the development, creation, and ongoing growth of a production quality Data Vault implementation with several of our features described below:
Environment management
Using our feature branching capability of providing many data engineers with their own data and code branch environment as the team grows in creating a Data Vault they will create new branches, then those branches will be merged as things go to production and new structures will be added to the production Data Vault.
Security
The DataOps.live data platform can manage even the most sophisticated security requirements. I wrote about implementing a Snowflake recommended security model for your production database in this article. I will not repeat much of that article, but there will always be a need to implement security around even the most carefully designed data model. Our platform eases the management of the role hierarchy and ensures that if a role has been dropped for some reason it will be redeployed the next time an orchestration is run.
Orchestration
Often there are several tools in an organization’s data ecosystem. Monitoring of load processes in an ETL tool, checking the status of testing in a test framework, ensuring that all the metadata is captured and published to the data catalog. Stringing together all these various disparate tools can be overwhelming and their importance can be undervalued by the data product consumers (trust me I know). With the DataOps.live data platform, our tool integrates all these things in a single framework. When adding new tools, it is a matter of writing a configuration file, then testing it in your feature branch. Once it works, merge the branch into dev, and start the process of promoting to production.
Testing
Ensuring the assumptions that are made about the data are in fact valid is crucial to ensuring the data is loaded, processed, enriched, and made available to the right people at the right time in the right format. If a test fails, you will be notified before the data product consumer. As with many of our customers your customers will come to support you when you say that stale good data is better than bad fresh data. As you grow the tests and learn more about the data that makes up your Data Vault you will be able to constantly run all these tests during every orchestration run. Wouldn’t you sleep better knowing that the data has been validated properly constantly? Or would you rather let your customers find problems with the data before you?
We can show you how our data platform can support a Data Vault implementation. Let us know how these features will help you in your production implementation. In the meantime, check out our #TrueDataOps Podcast series which features pioneers and thought leaders in the Data Vault and DataOps worlds!



