






We recently (14 July 2021) completed a masterclass with Kent Graziano, Chief Technical Evangelist, Snowflake, discussing Snowpark, the use of Scala and Java UDFs, and how we integrate this new technology into our DataOps platform. In particular, we discussed how we are using our Snowflake Object Lifecycle Engine to recycle these Snowpark objects through our DataOps platform via CI/CD pipelines and automated regression testing.
It was great to share our integration with Snowpark and Java UDFs. In summary, we are very excited about Snowpark because it represents a significant new way of thinking in the data world.
The philosophy of #TrueDataOps
While this blog post does not aim to deep-dive into the #TrueDataOps philosophy, it is worth taking a brief look, as our DataOps for Snowflake platform is based on #TrueDataOps.
When we developed our DataOps platform, we first started by defining our #TrueDataOps philosophy. We began with a pure, clean model of DevOps and CI/CD to create this philosophy. We took what worked, what didn’t work, and extended and built our #TrueDataOps philosophy on top of DevOps instead of creating DataOps as a new functionality.
Consequently, the most significant benefits of #TrueDataOps are applicable and relevant to both data and traditional software development.
Snowpark
Snowpark, Snowflake’s developer environment, provides developer and data engineers with the functionality to write, compile, and execute code inside Snowflake in their preferred language. In other words, Snowpark makes it easier to extend Snowflake’s functionality with custom Java UDFs and Scala code.
Snowpark’s primary objective is to move the execution of extended functionality closer to the data and significantly reduce the high-volume data movement in and out of Snowflake by storing the code files close to Snowflake’s compute engine.
The additional benefits of Snowpark include:
- Improve data security
- Significantly reduce costs
- Improve (or decrease) time-to-value
- Reduce operational overhead
The Snowflake Object Lifecycle Engine
Succinctly stated, we developed the Snowflake Object Lifecycle Engine (SOLE) to manage, recycle, and extend the life of every object found in Snowflake such as tables, grants, roles, constraints, sequences, shares, stored procedures, and user defined functions (UDFs).
The fundamental question that this masterclass answered is: How do we lifecycle Snowpark objects and Java UDFs as part of the DevOps infrastructure by citing the following scenario:
We started off with the following example of a pipeline (each number or step is a job in the pipeline):
- Secrets management: This job extracts the necessary credentials from secure tools like Data Vault
- Snowflake orchestration
- Ingest data
- Advanced processing: Compile, build, and execute Snowpark
- Advanced processing: Snowpark testing
- Business domain validation: Final data testing
- Generate docs

The two pipeline jobs that are relevant to this scenario are as follows.
The Snowflake orchestration job
This is where we build warehouses, roles, users, grants, shares, external functions, and resource monitors—all the objects required to make a Snowflake infrastructure work using the Snowflake Object Lifecycle Engine. Traditional SQL DDL (Data Definition Language) create and alter statements are very difficult to orchestrate. To solve this challenge, we model what the Snowflake environment must look like using YAML configuration files, including objects that hold the Snowpark output.
When the job containing the configuration files runs in the DataOps pipeline, it will build a complete Snowflake infrastructure if the environment is empty. If several objects do not yet exist or need to be altered or dropped, this engine will figure out how to replicate the model.
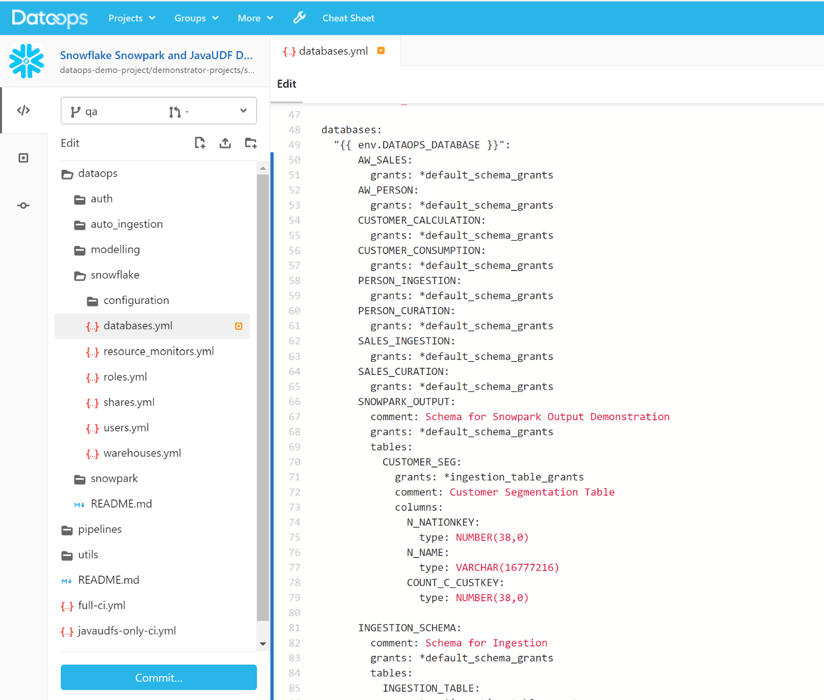
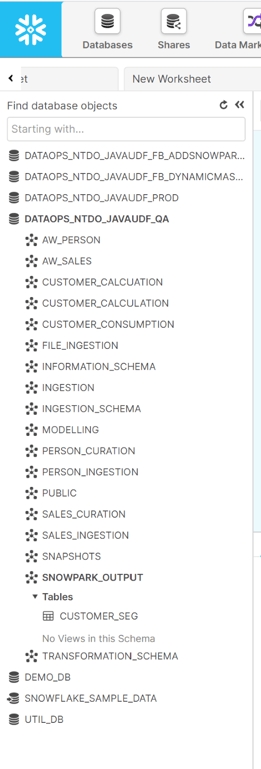
Advanced processing: Compile, build, and execute Snowpark
For this masterclass, we built a simple Scala job called customer segmentation. Very simply, it selects customer data from an ingestion table, filters it, joins this data to master data information, groups it, shows the result, and appends it to another table.
The Scala code consists of data frames. However, when we look at the output, we can see that SQL was compiled and executed. In summary, Snowpark decides on a case-by-case basis whether creating SQL statements or Java UDFs is best. We ask for the job to be done, and Snowpark does the rest.
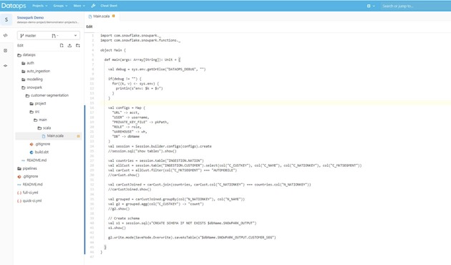
Conclusion
The key theme of this webinar is that Snowpark adds the standard software development requirements set out in the DevOps, CI/CD, and #TrueDataOps philosophies. Because our DataOps for Snowflake platform’s foundations are based on these paradigms, all this functionality is native to our platform.
Thus, the DataOps/Snowpark integration cycle is as follows:
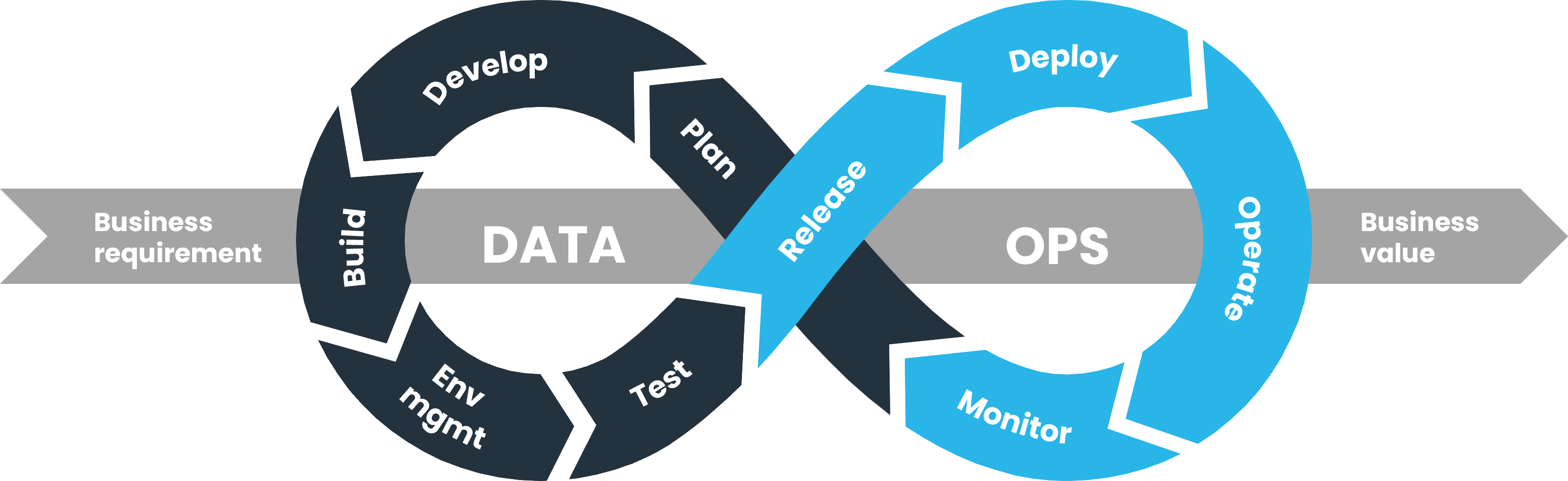
The question is: How do we build, Test, and Deploy Data Environments the same way we do software while maintaining all the core software DevOps capabilities?
Lastly, as described above, we are now using the Snowflake Object Lifecycle Engine alongside Snowpark to manage all the Snowflake objects that Snowpark needs to interact with.
For more details and technical information, watch the recording of this masterclass and connect with us here.
Ready to get started?
Access the latest resources on DataOps lifecycle management and support for Snowpark and Java UDFs from Snowflake.
