






Unless it’s on Snowflake with Instantaneous Demand
One of the standard promises of Cloud Data Warehouses when compared to their on-premises alternatives is elasticity. As your requirements go up and down, the system can stretch or shrink with them. All such systems are capable of change to some extent. The question is all about timing.
Changing the capacity of an on-premises Data Warehouse could easily take months (by the time hardware has been procured, installed, tested, and incorporated into a cluster). Cloud Data Warehouses offer a new approach where scaling is at the click of a button and can take just minutes. But does this really allow you to avoid overprovisioning or under-provisioning?
Time Series workload profiles
Time Series data usually has a very typical usage pattern, split into Read and Write.
Write
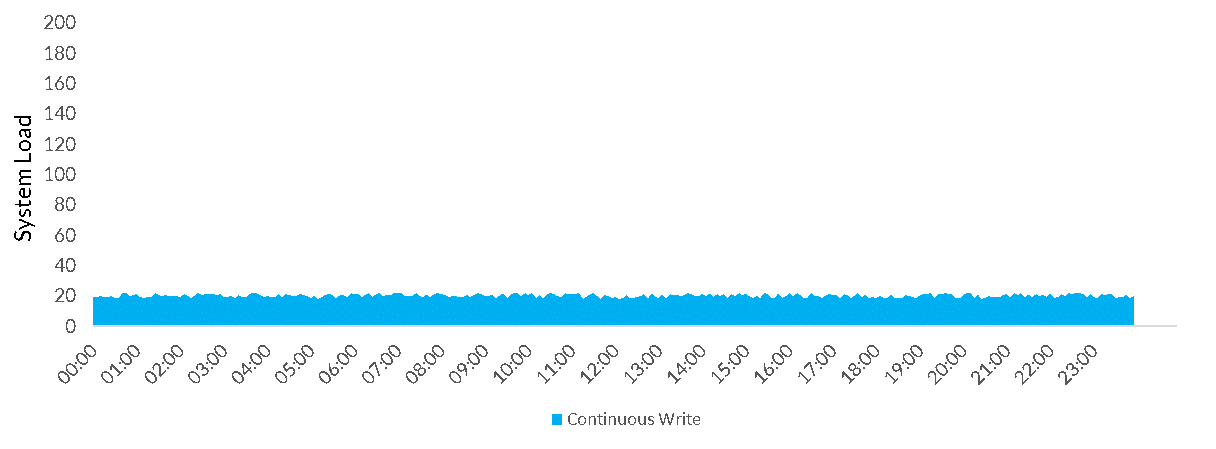
Write can happen anywhere between near continuously:
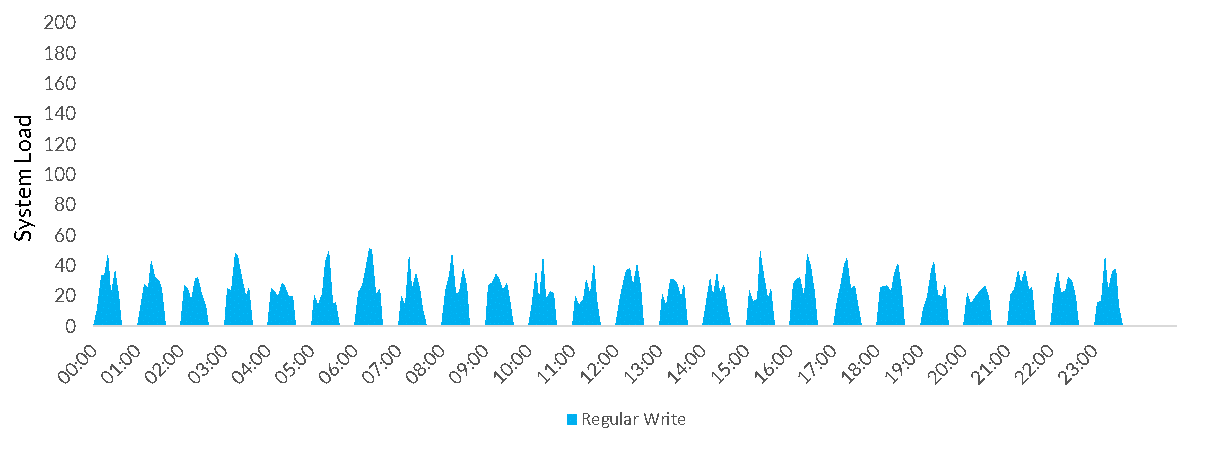
Very regularly (e.g. every 30 minutes):
Batch (e.g. every 24 hours):
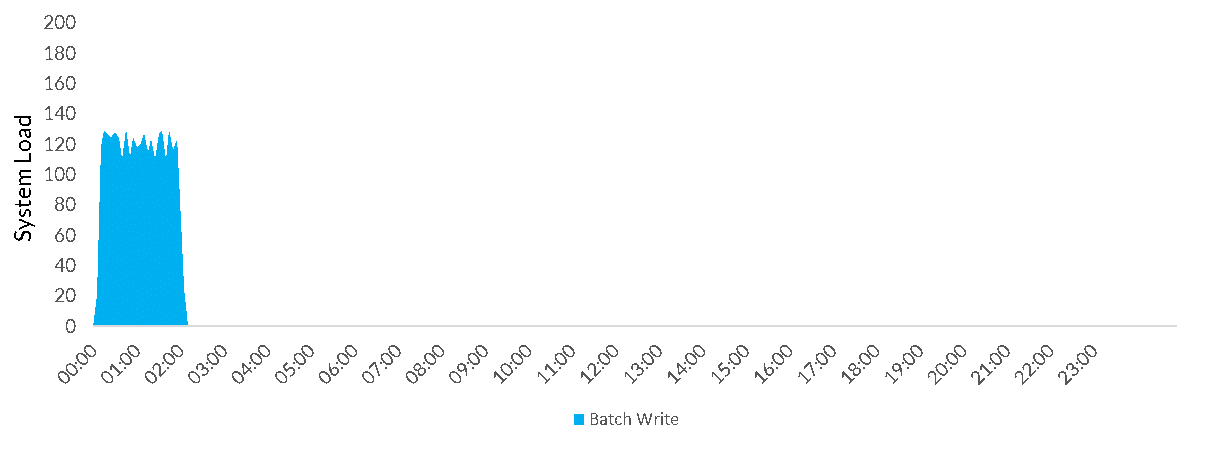
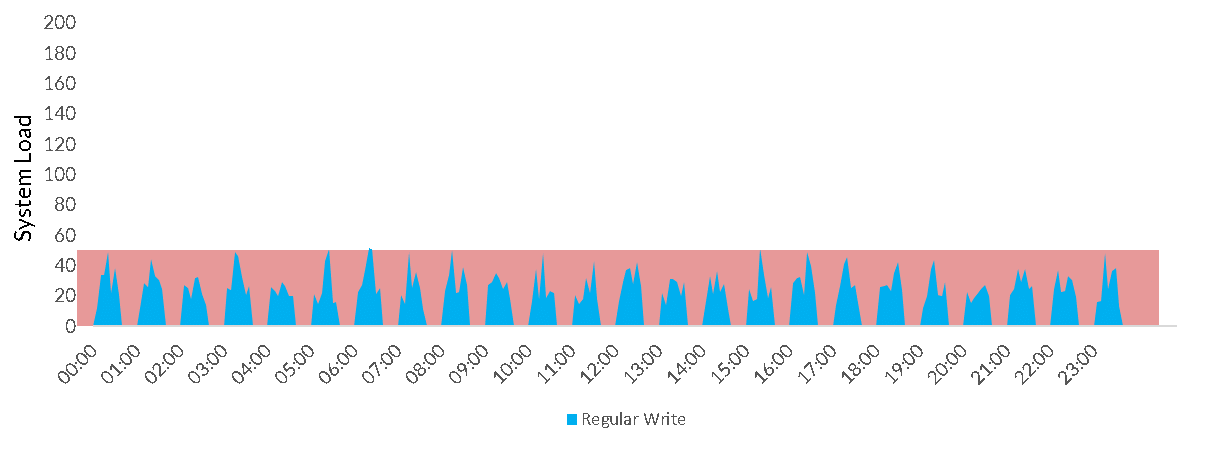
All of these workloads except continuous share the same problem: using traditional Data Warehousing sizing (i.e. how many servers do I have and how large are they) there is always a compromise to be made. If I provision for the peak load, I waste all the capacity when they the system is not being used e.g.
or
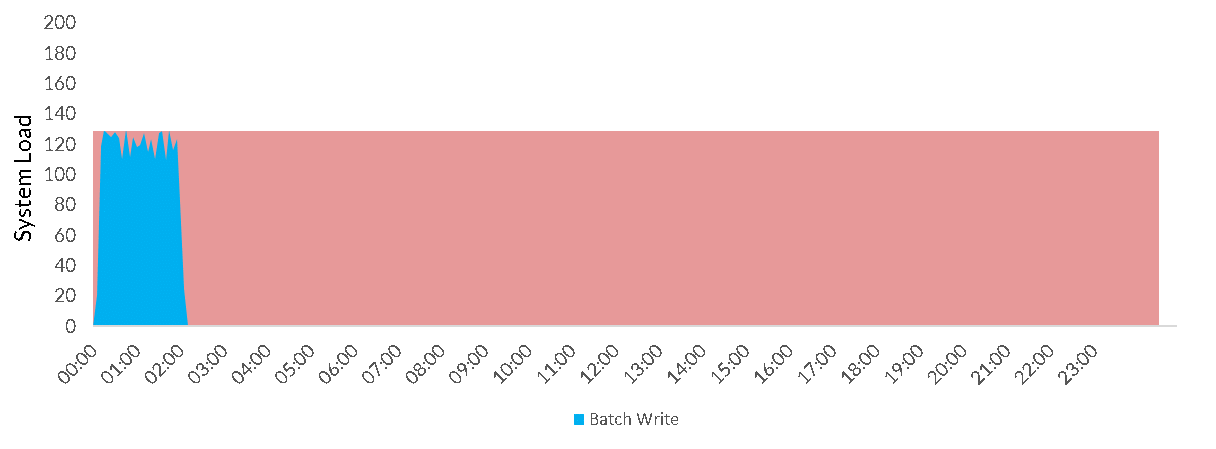
The problem here is that the elasticity time for traditional Cloud Data Warehouses is still measured in several minutes. It’s just about possible to consider resizing a Data Warehouse for a daily load, but practical limitations (often including some downtime while the switch is being made) make this very rare.
Read
Read Workloads are even more complex. In addition to a usual steady state of small queries (e.g. to update status pages, wall boards, KPI reports, etc.):
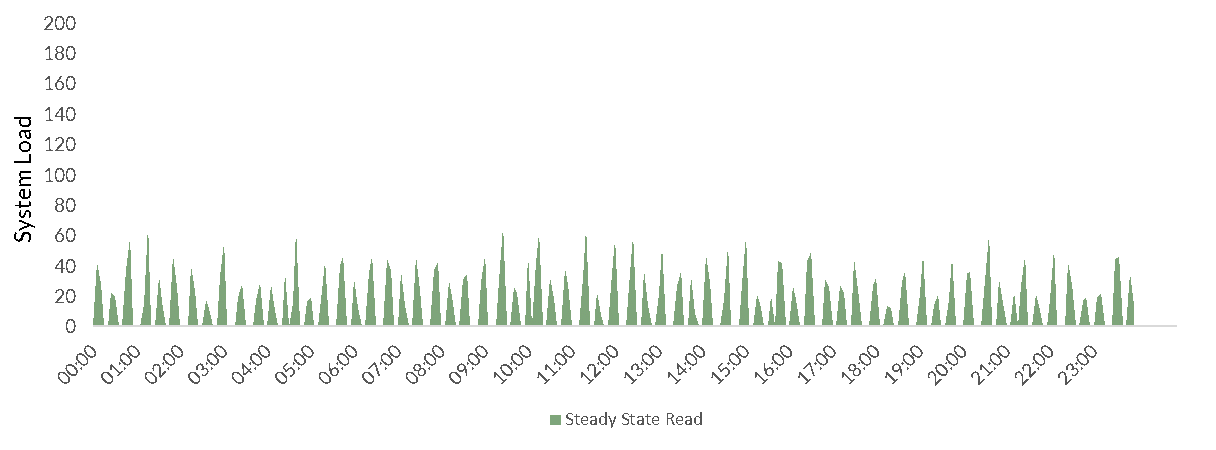
There are also the much more unpredictable, and often much larger queries driven by human usage (e.g. through a BI tool or Data Science Platform):
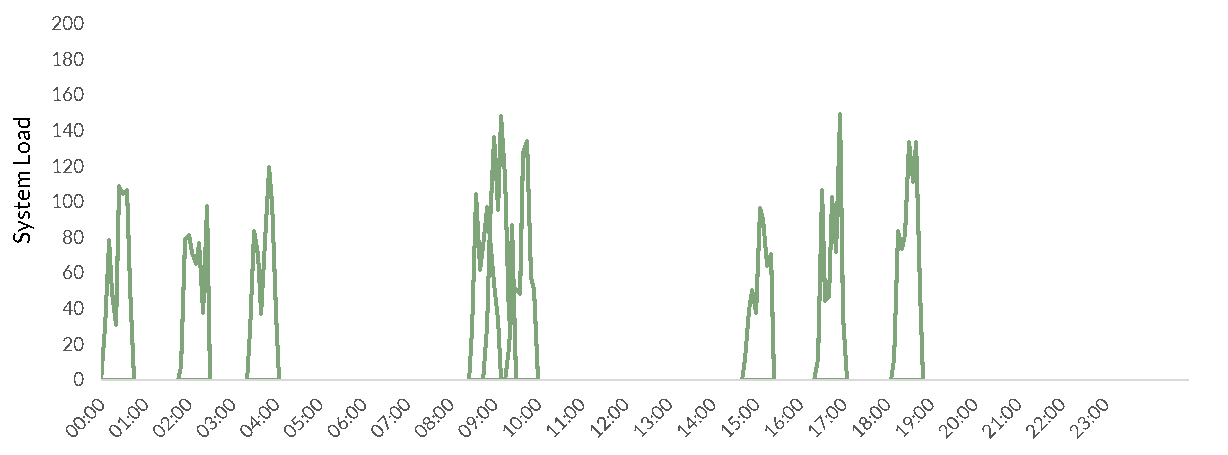
And of course, the real-world being what it is, these won’t spread evenly over time, or even over the working day, there will be large bursts of load (e.g. at 9am on a Monday morning when everyone wants to explore what happened over the weekend, or when there is an issue ongoing and everyone is trying to find out why). These will even overlap each other. So if we profiled the instantaneous desired system capacity at any one time it will be much higher than the peaks above:
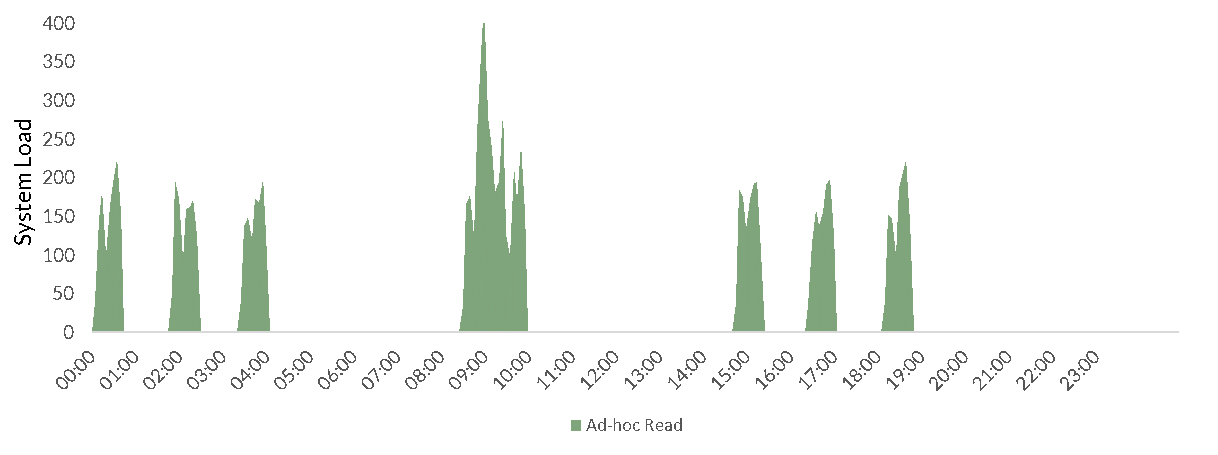
Of course, trying to size for the peak load here is incredibly wasteful:
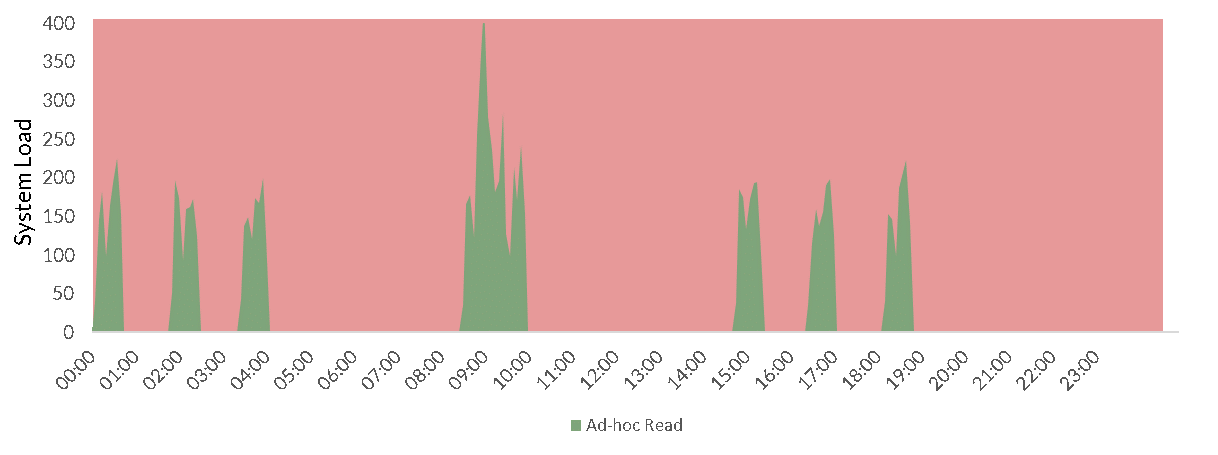
And yet not doing so will still cause possibly key users to slow down significantly.
Multiple workloads
In practice it’s unheard of for a Data Warehouse to have JUST reads or writes. In the real world they have both. This creates both an opportunity and a problem. If the reads and the writes occur at different times, then this can increase the effective utilization and reduce the wasted resource.
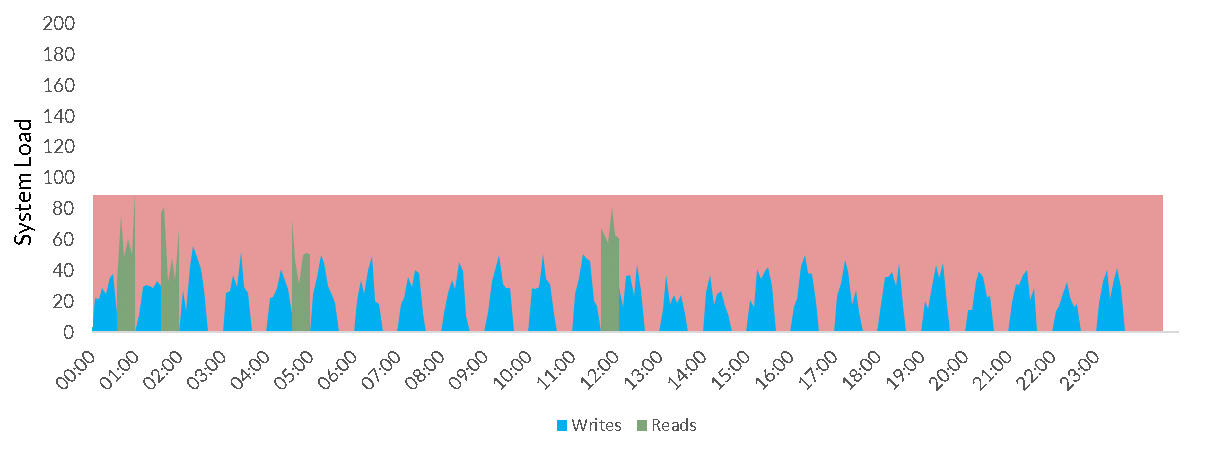
But is the real world ever so convenient? Absolutely not. In practical situations all the workloads, both read and write, will overlap each and interfere with each other and create a very bursty and unpredictable total demand with very large peaks.
The possible outcomes are
- The system will be overprovisioned and under-loaded. More capacity will exist than is needed by the total read-write demands. This is akin to burning money.
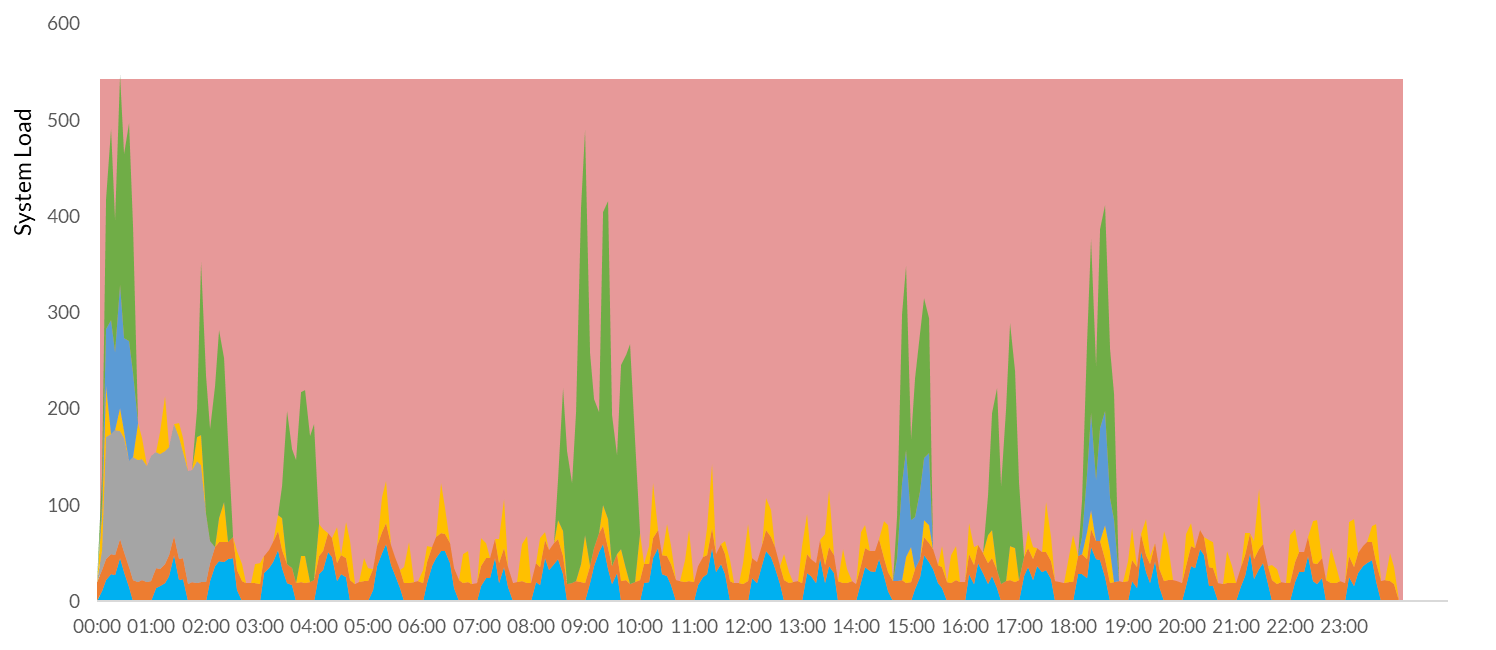
- The system will be under-provisioned and overloaded—the total read-write demands will exceed capacity; users will have to wait longer for results and write loads will be slowed down. In extreme, but all too frequent cases, this can hit a feedback loop—write queries fall behind, read queries time out and retry which increases system load. Write queries start to fail and fall further behind. Very quickly this loop will bring a system to its knees.
- Very, very rarely the system will have absolutely the right capacity for the user demands and will be both cost effective and meet all user demands.
Snowflake’s Instantaneous Demand
The problem here is all down to Elasticity. Even most modern Cloud Data Warehouses have elasticity models that are meant to flex based on trends (e.g. “this week I have more users than last week”, “this month we added new data loads, so we need to increase capacity”). What is really needed is a system that can respond to Instantaneous Demand.
The Snowflake Virtual Warehouse model provides exactly this capability.
In a continuous write model, a relatively small Virtual Warehouse can be provisioned ‘always on’. In a Regular or Batch load model a Virtual Warehouse can be provisioned for this load with Auto Resume and Auto Suspend; the Warehouse is only being paid for when it’s needed and being used.
In more complex load scenarios different Virtual Warehouses can be provisioned for each data set for example:
- Massive batch events being loaded daily: dedicated X-Large Virtual Warehouse with Auto Suspend and Auto Resume
- Regular Time Series loads every 30 minutes: dedicated Large Virtual Warehouse with Auto Suspend and Auto Resume
- Continuous Status Update loads: dedicated X-Small Virtual Warehouse always on
Critically, since each of these loads have their own warehouse, there is no contention between them (or between them and any read workloads).
Read workloads can be similarly provisioned:
- Updating wall boards every 60 seconds: dedicated X-Small Virtual Warehouse always on
- Hourly updating of KPI reports: dedicated Large Virtual Warehouse with Auto Suspend and Auto Resume
- Ad-hoc queries from Engineering users: dedicated X-Large Virtual Warehouse with Auto Suspend and Auto Resume and auto-scale of the cluster size
- Ad-hoc queries from Operations users: dedicated 2X-Large Virtual Warehouse with Auto Suspend and Auto Resume and auto-scale of the cluster size
- CFO finance reports: dedicated X-Large Virtual Warehouse with Auto Suspend and Auto Resume—when the CFO wants their report, they don’t want to wait in line. So why make them?!
Ultimately, this creates an architecture where workloads are modelled, distributed based on some key attributes (some of which have been discussed here and some of which are out of scope of this blog post like cache hit frequency) and they are provisioned as specific Snowflake Virtual Warehouses. This creates a system where capacity follows demand very closely (certainly sub 60 seconds) and creates the true win-win: All read-write workloads get the capacity they need when they need it.
