Let's dig in to data mesh




The four Data Mesh Principles
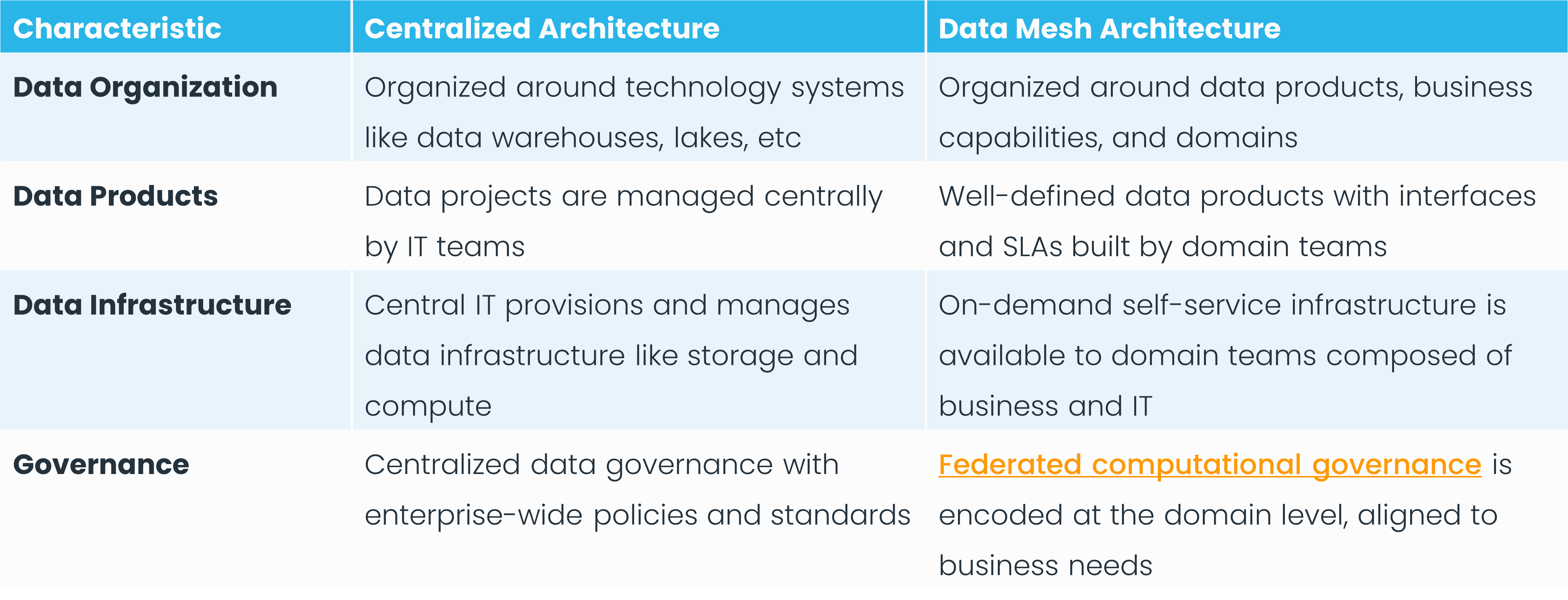
When Zhamak Dehghani developed the distributed data mesh architecture, she outlined four separate but interrelated principles designed to achieve its goals:
Domain-oriented data ownership
Data ownership has become an important consideration as organizations strive to become data-driven. The domain-oriented data ownership and architecture approach of data mesh seeks to address this goal by giving the business teams closest to the data the responsibility of managing it.
By giving domains ownership of their data, you decentralize the responsibilities that would traditionally lie with a centralized data team. This allows for more agility and responsiveness to specific business needs.
Data as a product
Data mesh calls for a fundamental shift in how organizations think about data. Instead of looking at data as a byproduct or secondary asset, organizations treat data as products that require as much attention, planning, and care as any other product. This means it must be well-defined, reliable, and fit for purpose.
A data product owner works with a clear set of stakeholders to define the use cases it aims to support. They then manage the entire product lifecycle, ensuring the data product remains relevant, up-to-date, and aligned with their stakeholders’ evolving needs. And since data product owners deeply understand how their customers use their data products and the data itself, data value increases.
What is a data product? Get an in-depth introduction here!
Self-service data infrastructure
Data mesh requires a self-service data platform for successful implementation. Self-service infrastructure alleviates bottlenecks often associated with centralized data teams. It should contain all the tools and technologies domain teams need to build, deploy, and maintain data pipelines, applications, and products.
However, for decentralized self-service infrastructure to work across an enterprise, all teams must use a set of standardized tools and practices. This ensures consistency and makes it easier for teams to collaborate and share data. In a self-service environment, it's also important to have mechanisms for tracking usage and associated costs to make sure resources are being used efficiently and for better planning and allocation of data storage and processing capabilities.
The self-service environment also needs to be accessible for non-technical users. User-friendly interfaces like dashboards or other visualization tools that make it easy for business users to derive value from data are essential. It's also crucial that data is easily discoverable. This often involves creating a data catalog listing all available data products, metadata, quality metrics, and other relevant information.
Federated data governance
Data mesh uses a federated system of governance that aims to balance centralized oversight with decentralized data ownership. Unlike traditional models where a central team governs all data, federated governance distributes some of this responsibility to domain or business unit teams. Each team is accountable for the quality, security, and compliance of its own data within the framework of organization-wide policies and standards.
This approach allows for more agility and specialization, as individual teams understand their data best. However, it also calls for standardized tooling, metrics, and protocols from the central team to provide consistency and compliance across the organization. Federated governance thus combines the best of both worlds: it maintains global standards while empowering local teams to be more responsive and innovative.
Take a deeper dive into the importance of federated governance in data mesh.